RXS mainframe scripting language
for z/OS
A Mainframe is the handler
of a very large DB2-system. Historically, mainframe has been a lot of other
things, but today this is the important – and only – niche of the mainframe.
The mainframe supplies the processing power and the storage needed to run the
DB2-system, and COBOL or Java supplies the logic web connecting the different
SQL-calls. 'Server-parks', 'cloud', 'no-SQL datastores' are other concepts that
it-solutions may revolve around, but the large, integrated DB2-database
still has its market, and with it: the mainframe has a market. 'Integrated'
means that a centralized commit mechanism exists.
All established scripting languages
on the z/OS mainframe – most notably REXX, Easytrieve,
FileAid, FileManager - are
from a time before DB2 was the king of the mainframe, and accordingly these
languages have a focus on handling sequential files. Around 1990 these
languages have been supplemented with DB2-interfaces, but these interfaces are
additions, they are not integrated in the fundamental syntax of the languages.
You can make the same complaint
about COBOL and Java: SQL-interfaces are additions, and not part of the
fundamental syntax of the languages. And you could further invalidate my
argument by saying that this is just the way it should be: The procedural logic
of COBOL and Java should not be mixed with the imperative logic of SQL; COBOL
or Java describing step by step how to reach a conclusion, SQL just asking the
question to pull the conclusion: ‘Does the database contain any red-haired
persons with a weight of exactly 101 kg?’ (as
example). But a scripting language should focus on short formulation, and
without that capability in the language, you might as well solve the problem in
COBOL or Java. The common mainframe scripting languages use the COBOL-way of
interacting with DB2: Define a cursor, open it, fetch until no more data, and
close it. That is not very ‘scripting’ like.
Now let's focus on RXS:
Historically, the development of the RXS scripting language is a side effect of
a very large (> 40 developers) project which started in 1991. The project
was, and is, serving the Danish tax administration. Two problems got focus on
the development process: The need to automatically generate a lot of COBOL coding,
and the project’s stated policy of a strict DB2 focus. Both problems pointed to
the flaws in the common scripting languages of the mainframe. Code generation
on mainframe via REXX plus File-tailoring services plus ISPF-skeletons works
fine, but it is complicated, and is not intended for quick ad hoc solutions. RXS
offers a less complicated solution, both for ambitious and for quick
approaches. DB2 access via REXX also works fine, but the abstraction is not thoroughly
enough: You must deal with details in the interface instead of just focusing on
the SQL-syntax. In both cases: code
generation and DB2 access, RXS offer a better abstraction.
Handling of other ‘modern’ data
formats: XML, MQSeries and UNIX-files on mainframe are integrated in RXS. Again
'abstraction' is the word: RXS offers a common syntax spanning all these
data-sources on the mainframe, including DB2 and code generation. A common
syntax also means a thoroughly programming of error handling: Error messages,
also from subsystems (DB2, ...) are
always in English (not just codes), and handling or bypassing of errors are
done the same way, regardless of which data-source or data-sink is used. 'Commit'
is handled across all data-sinks.
RXS is built on published IBM
interfaces to the mainframe, thereby securing that IBM's guarantee for forward
and backward compatibility on the mainframe also is covering RXS. Together with
a syntax stable (but extended) since 1995, RXS has full forward compatibility:
A script written in RXS today will function the same way 25 years from now –
just like a RXS script from 1995 works today.
RXS itself is written solely in COBOL and REXX, so any optimizing and
lifting of constraints in these two languages by IBM, will benefit RXS without
any adjusting of the source-code of RXS. For instance, to enter the 64-bit
addressing in COBOL, only a recompile of the COBOL part of RXS is needed (But
this offers no advantages for now). A more relevant example is that REXX are better
at handling large data files since MVS release V2R1, and this has lifted some
constraints in RXS programs as well.
The syntax of RXS is based on the
concept of a pipeline language. A pipeline is the defining concept for UNIX,
but normally not used in z/OS outside UNIX. This concept places RXS apart from the
classes of well-known contemporary languages like Java: RXS is not
object-oriented. Instead, it has a focus on handling data stores outside the
language (DB2 for instance), seeing these as 'pipes'. Internal data stores in RXS
are 'pipes', and 'pipes' (or data-streams) are the main abstraction - the
common syntax - in RXS: 'RXS sees everything as pipes'. Strictly, there is a
difference between RXS and UNIX here: RXS normally see a pipe as a collection
of structures (records), while UNIX normally see a pipe as a collection of
bytes or bits. The two views meet when a UNIX-pipe is viewed as separate
structures using 'new-line' characters between these.
RXS is ‘open source’: The source
code of the language is published here on this website. The development of RXS
is done, and the costs has been paid for. A broader use base for RXS could
benefit the project by creating more discussion on RXS, and by creating more
knowledge of the pros and cons of the language.
RXS is in the group of scripting languages, like REXX and Easytrieve - you can program any logic in these languages. The
other languages mentioned above: FileAid and FileManager, are not languages, but rather collections of
separate scripting mechanisms.
RXS uses ISPF (3270) interfaces to
the mainframe. Using PC-interfaces (Ellipse based and other) is possible when
using RXS in batch, but a major strength of RXS is using the concept
interactively under ISPF.
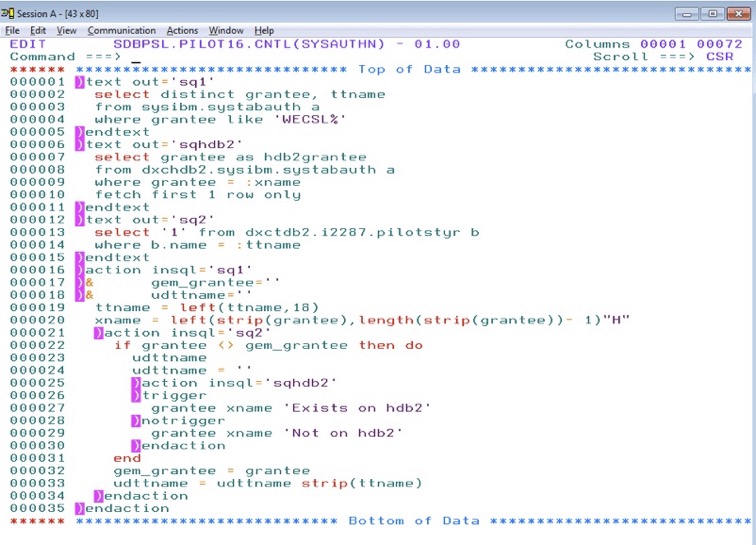
A RXS example: A script checking
some relations across 3 different DB2-systems (test, pre-production
and production), making a report on its findings. This is not an easy read, but
what other language could query different DB2-systems in a coding of 35 lines?